 |
|||||
|
Implementation: Infrastructure:
|
ComponentizeThere are many ways to design data-management. When many parties have to share data in complex projects, you must break the problem up into manageable components. Each component has its own purpose, and works in some legal environment. 
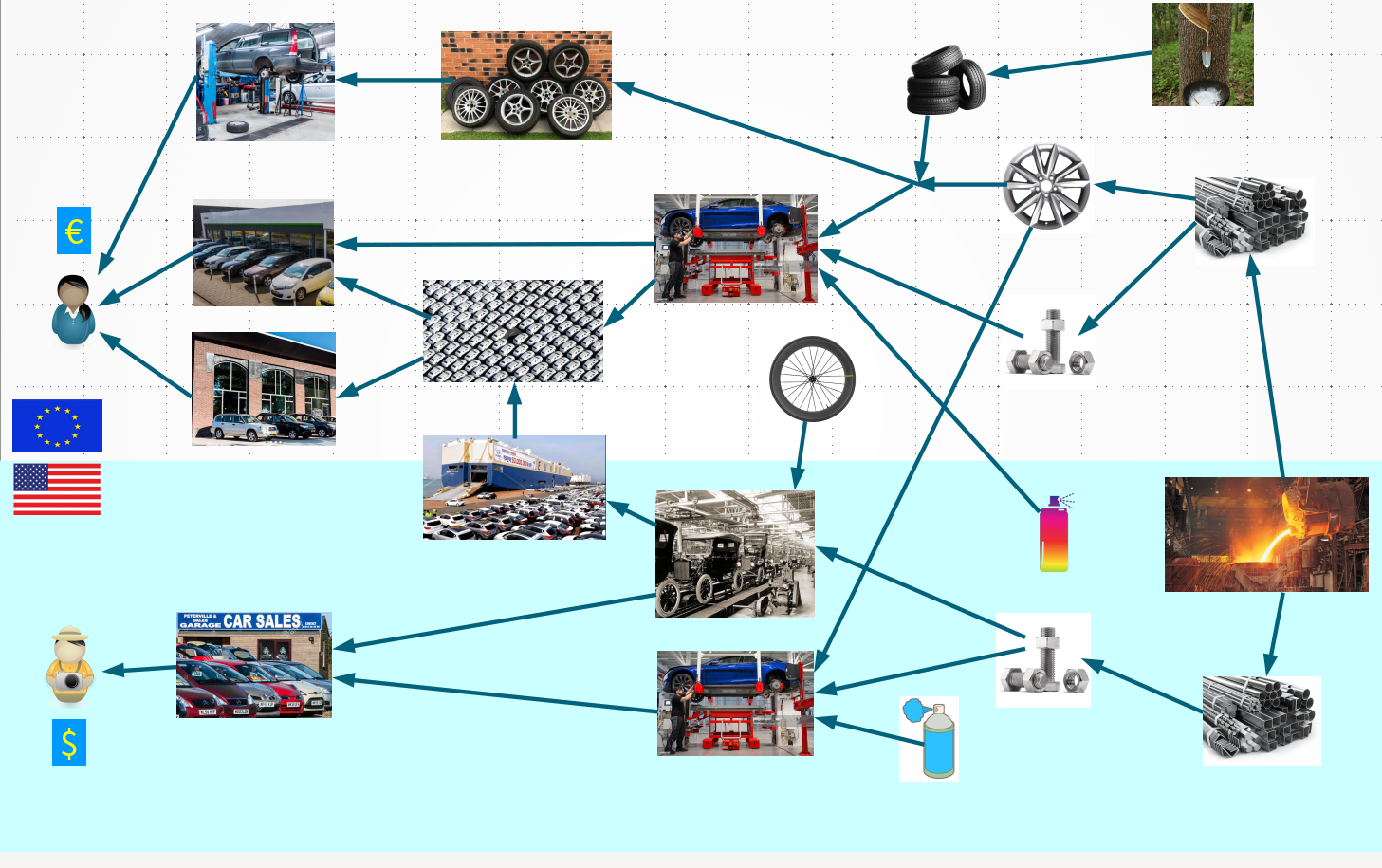
Meshy Space seems the only solution for the huge quantities and complexities, which are expected in projects related to the construction of an European search engine, as constructed by the Open Search Foundation. Especially for exchange of crawled website pages, and the exchange of website knowledge via Open Console (a Google Search Console competitor). Primitive Big-Tech approach: mono-polyMeshy Space has its focus is on simplifying Open Cooperation on a huge scale. Cooperation is created by permitting everyone to create data-sets for larger integration.When you compare the billion dollar business of evolved art of car manufacturer with the billion dollar business of young Big-Tech, you see the huge difference:
The car construction business is built from many specialized businesses, which need to compete on quality and efficiency of their car part. Big-Tech does not use these dynamics: they keep all in one hand. The expenses to create a full competitor for them are too high. Specialized improvements cannot be developed by third parties, so are not created. New ideas cannot be monitized, so are not developed. To be able to create a real competitor for Big-Tech in the foreseeable future, we need to start constructing those specialized components. Create them in such a way that they have some use now, and can be glued into larger applications later. Towards an Open Network of CooperationYou may prefer other ways to organize cooperation, but these are explicit choices made to build an open network:
Feed-based Shopping/Factory ModelIn our non-Internet economy, you have producers and consumers. Producers which specialize in product can improve them faster and produce cheaper. This is exactly the problem with the current monolithic BigTech: there is no healthy competition on parts of their products. This hinders evolution, hence progress of internet. Normal shops and factories work demand driven: a consumer orders products with a contract, which get delivered over time. Consumers may have overlapping needs, which makes production more efficient. Some products need pre-order, be in stock for a limited time, or taken out of assortment.
There are many extensions to existing message exchange protocols, to make flexible feeds possible. Continue reading about the constructs in the messages which build these feeds. mark@overmeer.net Web-pages generated on 2023-12-19 | ||||
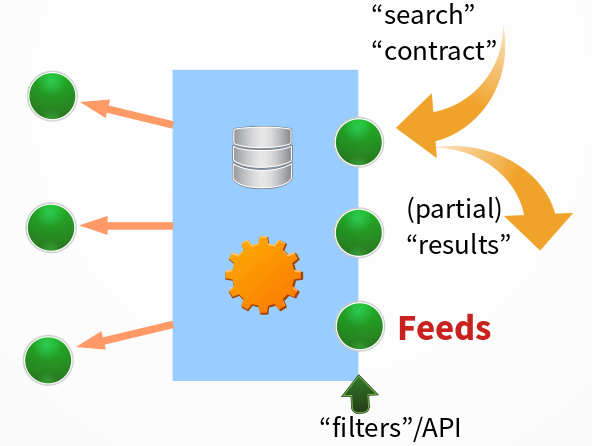 The generic structure of a component is shown on the right. The arrows
indicate the direction of action: the consumer takes action to collect the
information it needs. The data flow is therefore in the other direction:
these are strictly "pull" interfaces.
The generic structure of a component is shown on the right. The arrows
indicate the direction of action: the consumer takes action to collect the
information it needs. The data flow is therefore in the other direction:
these are strictly "pull" interfaces.